
プラント屋の友人曰く、現場では計測値を手書きで記録して、後でデータ入力なんてのを日常的にやってることもままあるらしく、OCRで効率化したいそうで、(無料で)できるかどうか試してみました。
記事の内容を要約すると、
・Tesseractで手書き数字の認識にトライ→Bad
・ニューラルネットワークで手書き数字の認識にトライ→Bad
(環境:Windows10)
最初、オープンソースのOCRライブラリTesseractで自分の文字を試したものの、正解率が低くく、自分の字の正解率は4、5割程度でした。
そのあと試しにPyTorchによるニューラルネットワークで、手書き数字のデータ集MNISTを使って機械学習した結果、MNISTデータ上は正解率95%以上だけども、自分の字だと79%くらいになりました。4などの特定の文字が苦手らしく、実用は難しそうでした・・・。
Tesseract-OCRによる手書き数字の認識
下記からWindows用のインストーラーをダウンロード
https://github.com/UB-Mannheim/tesseract/wiki
64bit版v5.0.0aをインストールしました。
PythonでOCRを実行する方法
https://gammasoft.jp/blog/ocr-by-python/
上記サイトを参考にし、画像1枚に数字が1文字あることを想定しているため、
BuilderをDigitBuilder、layoutは10で実施。
Builderの種類:
TextBuilder 文字列を認識 WordBoxBuilder 単語単位で文字認識 LineBoxBuilder 行単位で文字認識 DigitBuilder 数字 / 記号を認識 DigitLineBoxBuilder 数字 / 記号を認識
layoutの種類:
0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character.
ソースコード:
# -*- coding: utf-8 -*-
import os
from PIL import Image
import pyocr
import pyocr.builders
def main():
path_tesseract = "C:\\Path\\Tesseract-OCR"
if path_tesseract not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + path_tesseract
tools = pyocr.get_available_tools()
tool = tools[0]
builder = pyocr.builders.DigitBuilder(tesseract_layout=10)
f = open('test.txt','w')
dir_path = "./img_src/"
file_list = os.listdir(dir_path)
i = 1
for fname in file_list:
path = os.path.join(dir_path,fname)
if os.path.isfile(path):
img = Image.open(path)
img = img.convert("L")
result = tool.image_to_string(img, lang="eng", builder=builder)
if result == '':
result = 'x'
print(fname+':'+result)
f.write(result+' ')
if i % 10 == 0:
f.write('\n')
i += 1
f.close()
if __name__ == '__main__':
main()
自分の手書き文字の識別結果
文字はこんな感じ

1文字1文字切り取って2値化処理しました。

同じ数字が10枚あります。
2値化処理だけ行った場合の認識結果が以下です。
0: 0 0 x x x x x 0 x 0 1: x x x 4 4 x x x x x 2: 2 2 2 2 2 x 2 x 2 2 3: 3 3 3 3 3 3 3 3 3 x 4: x . x x x x 4 4 x x 5: x x x 5 x 5 5 x x x 6: x x x x x x x x x x 7: x x 7 x 7 x 7 7 7 x 8: x x x x x x x x x 0 9: 0 x x x 4 x x x x 7
なんとも残念な結果。2と3はわりと得意なようです。一番単純な1を認識しないとはこれ如何に?
文字を中央に寄せて、文字高さが80%くらいになるように余白を調整して、28×28にリサイズした結果が以下です。
0: x x 0 x 0 6 x x x x 1: x x x 4 4 x x x x x 2: 2 2 x 2 2 x 2 x 2 2 3: 3 3 x 3 3 3 3 3 3 3 4: 4 x x 4 4 4 4 x 4 4 5: x x x 5 x 5 5 x x x 6: 6 x 6 6 6 x x 6 x 6 7: 4 7 7 7 7 4 7 7 7 4 8: x x x x x x x 8 x 5 9: x 9 9 x x x x 9 x x
やや良くなりましたが、大差ないですね。4とか6も少し認識するようになりました。
NMISTを使ったTesseract-OCRの再学習について
Tesseractは手書き文字は目標にないらしく、再学習させることで手書きの認識率は上がるらしいです。だけども、情報はあるものの学習させるのがちょっと難しそうだし、時間がかかる・・・。ってことでしないことにしました。以下の情報によると、学習させると90%くらいになるらしい。
Tesseract handwriting with dictionary training
https://stackoverflow.com/questions/12310287/tesseract-handwriting-with-dictionary-training
Tesseract 4.1にLSTMを使って手書き文字を再学習させる
https://qiita.com/aki_abekawa/items/c2b94187f2ba7dc56993
TESSERACTのTRAINEDDATAを作る
https://minimashia.net/create-tesseract-traineddata/
ニューラルネットワークによる手書き数字の識別
調べている内に、手書き数字の機械学習は入門的な情報が多いのに加えて、文字を線化して角度情報を含めて学習させたらどうだろうと思い、やってみたくなりました。そこで、手始めにニューラルネットワークによる手書き文字の認識をしてみました。
ライブラリはPyTorchを使いました。なんとなくわかりやすそうな気がしたので。
PyTorchのインストール
公式サイトでpipコードを作成してインストールしました。
https://pytorch.org/get-started/locally/
ちなみに以下のコードはWindowsでは不可らしく、インストールしようとすると、このモジュールが無いなど怒られます。
pip install torch torchvisionERROR: Command errored out with exit status 1:
No module named ‘wheel’
No module named ‘tools.nnwrap’
モデル構築とMNISTの学習
モデル及び学習方法は下記サイトの丸コピです。
【PyTorch入門】PyTorchで手書き数字(MNIST)を学習させる
https://rightcode.co.jp/blog/information-technology/pytorch-mnist-learning
ただし、学習したパラメータを保存するために下記のコードを処理の最後に追加しました。
torch.save(net.state_dict(),'my_mnist_model.pth')Pytorchでモデルの保存と読み込み
https://tzmi.hatenablog.com/entry/2020/03/05/222813
学習済みのデータを読み込んで画像を認識させるソースコードが以下です。
# -*- coding: utf-8 -*-
import os
import torch
import torch.nn.functional as f
import torchvision
from torchvision import datasets, transforms
from PIL import Image, ImageOps
class MyNet(torch.nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc1 = torch.nn.Linear(28*28, 1000)
self.fc2 = torch.nn.Linear(1000, 10)
def forward(self, x):
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
def predic(data):
net: torch.nn.Module = MyNet()
net.load_state_dict(torch.load('my_mnist_model.pth'))
net = net.eval()
output = net(data)
_, prediction = torch.max(output, 1)
print('result=' + str(prediction[0].item()))
def image_loader(path):
image = Image.open(path)
image = image.convert('L').resize((28,28))
image = ImageOps.invert(image)
image.save('test_input.png')
transform=transforms.Compose([
transforms.ToTensor(),
#transforms.Normalize((0.5,), (0.5,))
])
data = transform(image)
data = data.view(-1, 28*28)
return data
def main():
img = image_loader('img/0-0.png')
predic(img)
if __name__ == '__main__':
main()
Pytorch×MNIST手書き数字認識 PNG画像を入力に予測してみる
https://qiita.com/oyngtmhr/items/ad5e1932ab4807dc0963
PyTorch MNIST [CNNを学習]
https://qiita.com/TKC-tkc/items/42ff569be496621fc016
Pytorch 学習済みモデルで識別[MNIST]
https://qiita.com/TKC-tkc/items/3b41620ecb9b22901413
手書き数字の識別結果
MNISTのデータは扱い方がチンプンカンプンですので、画像で変換してもらっているものをダウンロードしました。
MNIST converted to PNG format – GitHub
https://github.com/myleott/mnist_png
試しにちゃんとできているか確かめるためにtesting dataの正解率を見てみたところ
0:99.29 % 1:99.30 % 2:97.29 % 3:98.51 % 4:95.82 % 5:97.20 % 6:97.60 % 7:97.37 % 8:98.05 % 9:98.12 %
95%以上の正解率。4が少し苦手で9になることがままある感じ。
さて、自分の字ではどうか?
0(100%): 0 0 0 0 0 0 0 0 0 0 1( 80%): 1 1 1 2 1 1 1 1 1 6 2(100%): 2 2 2 2 2 2 2 2 2 2 3(100%): 3 3 3 3 3 3 3 3 3 3 4( 40%): 9 4 4 4 9 9 9 4 9 9 5( 60%): 2 5 5 5 8 5 5 5 0 2 6( 70%): 6 6 8 6 8 6 5 6 6 6 7( 70%): 7 7 3 7 7 7 7 3 7 9 8( 90%): 8 8 2 8 8 8 8 8 8 8 9( 80%): 9 9 9 9 9 9 9 7 2 9 total: 79%
実用的とはいかないまでも、デフォルトのTesseractよりは良いです。やっぱり4が苦手ですね。
ちなみに前処理として、文字のサイズ(高さ)を画像の71%になるよう調整しています。なぜ71%かというと、NMISTのサイズ率を調べると平均的にそれくらいだったからです。
文字サイズの調整をしてなかったら元より、80%にしただけで正解率は59%に落ちてしまいます。うーん、デリケート。
さて、これは練習で、本当にしたいのは、数字を線化して、線の方向を入力データとして加えたら精度が上がるか?という検証です。とりあえず別のライブラリも使い、線化させるとこまではできました。
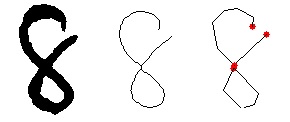
でも、ここまではコピペでできましたが、PyTorchのデータセットを自前で作って学習となると、いよいよソースコード・データ形式の理解が必要です。すぐにはできそうにないので、記事はここまでにします。続くかどうかはわかりません。続けー
追記:続いた!